数据分析与应用课程大作业网络安全 / 涉网犯罪预警
PHISH
Public Phishing URL Dataset
基于公开钓鱼网站数据的网络钓鱼识别与风险特征分析
面向涉网犯罪预警的分类、聚类与关联规则研究
面向涉网犯罪预警的分类、聚类与关联规则研究
犯罪分子通过伪造银行、电商、社交平台或政务服务页面,诱导用户输入账号、密码、验证码、银行卡信息等敏感内容,进而实施盗号、盗刷、诈骗引流或个人信息非法获取。
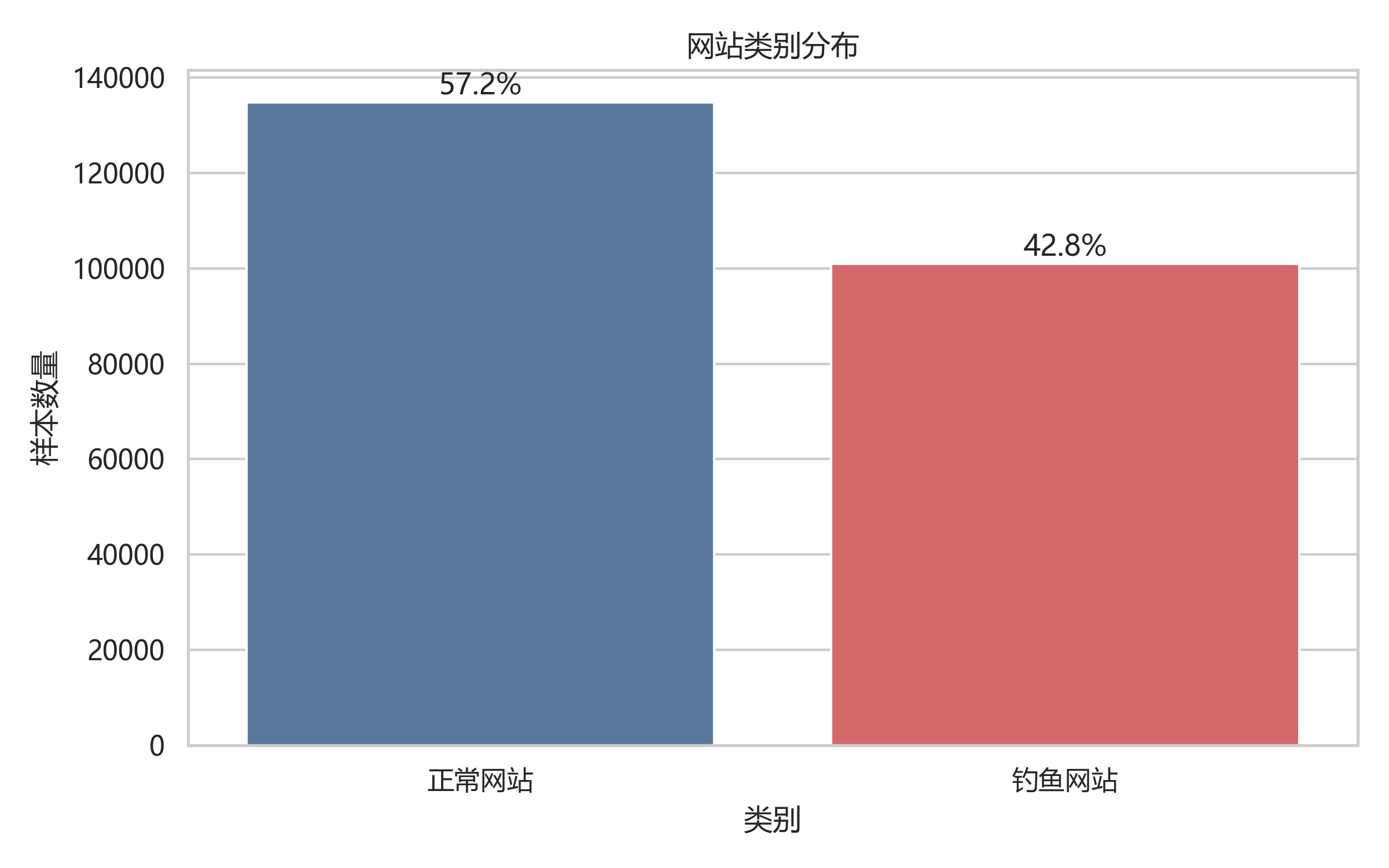
正常网站 134850 条,钓鱼网站 100945 条,两类样本数量均较充足,不属于严重类别不平衡。
| 分析任务 | 方法 | 输出结果 |
|---|---|---|
| 数据准备 | 标签统一、派生特征、离散化 | 63 个分析字段 |
| 描述统计 | 类别分布、相关性、组间差异 | 57.19% / 42.81% |
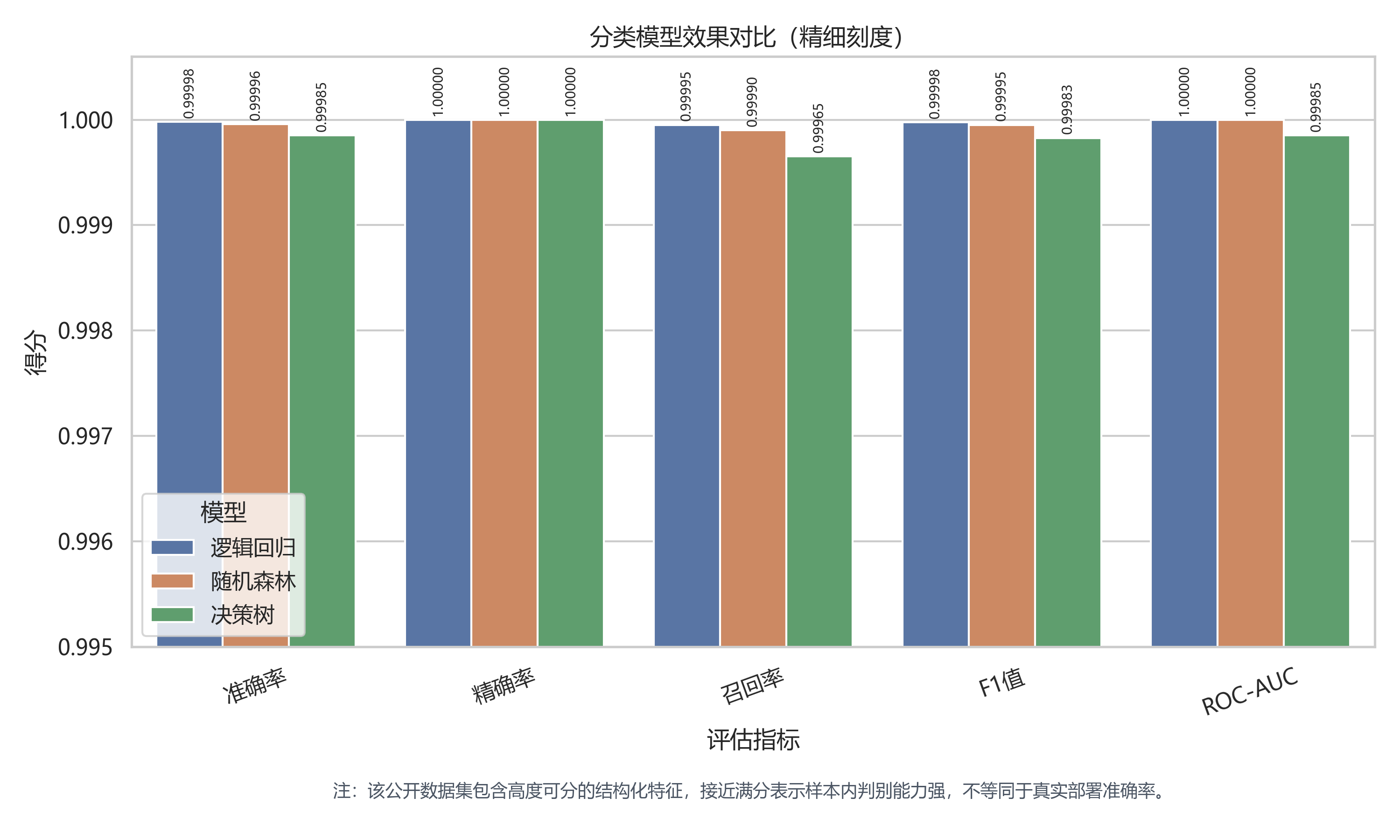
| 分类识别 | 逻辑回归、决策树、随机森林 | 最佳 F1=0.999975 |
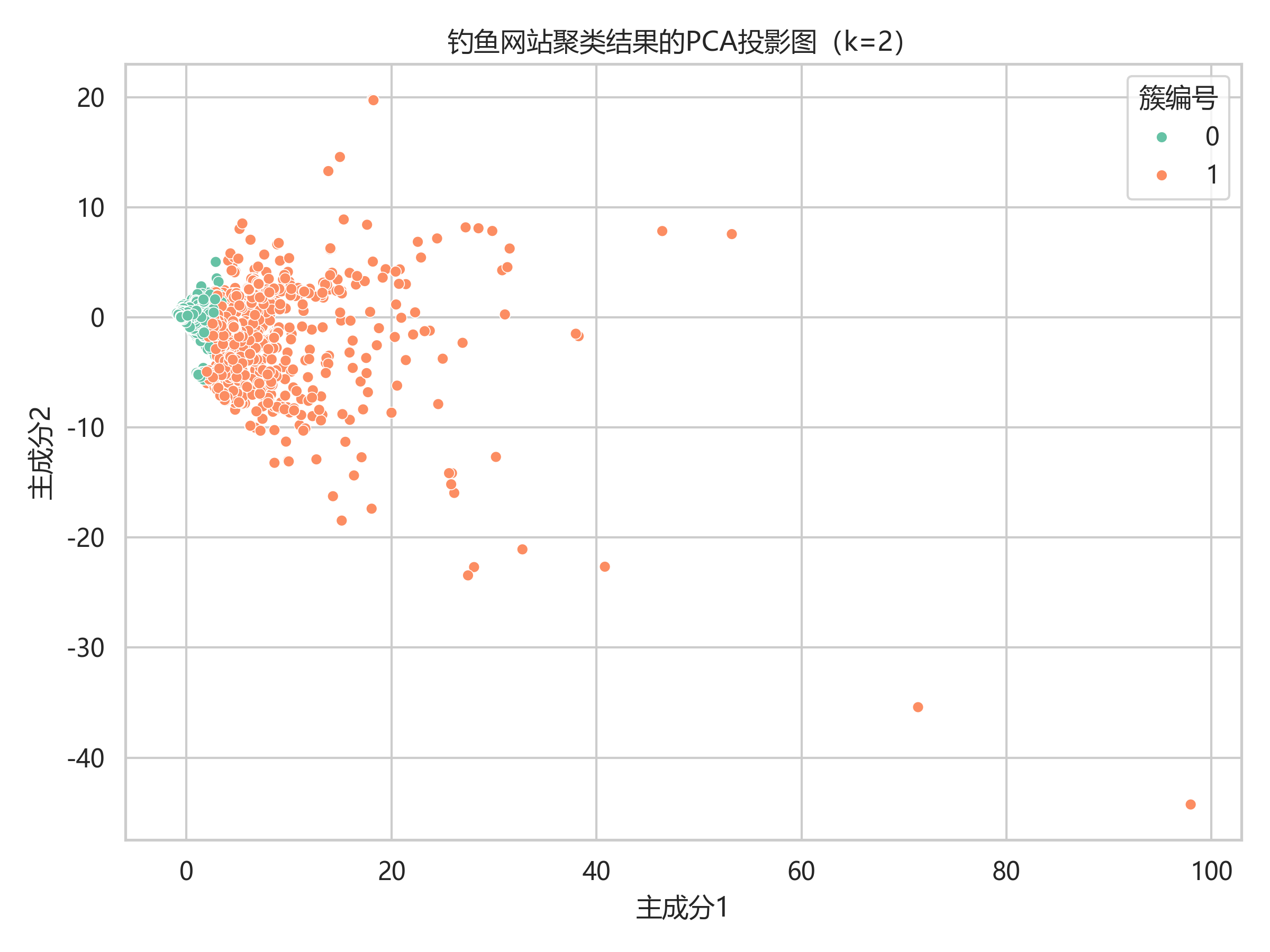
| 聚类分析 | KMeans + 轮廓系数 + PCA | k=2,轮廓系数 0.749350 |
| 关联规则 | Apriori + confidence/lift | 最高提升度 2.335876 |
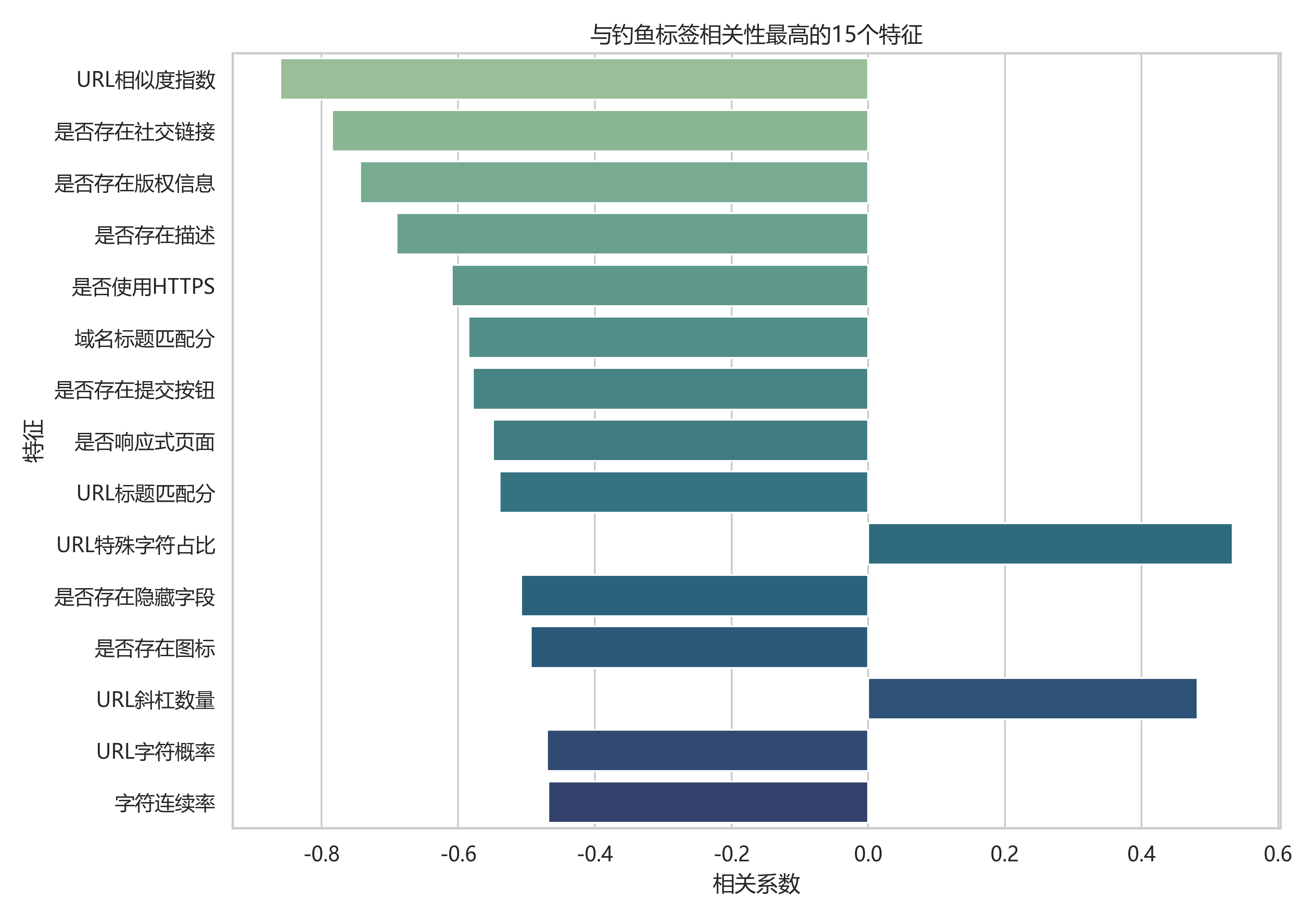
负相关表示这些正常网站常见特征越明显,样本越不倾向于被标记为钓鱼网站;特殊字符占比为正相关,说明高特殊字符 URL 更常与钓鱼标签同时出现。
| 模型 | 准确率 | 召回率 | F1值 | ROC-AUC |
|---|---|---|---|---|
| 逻辑回归 | 0.999979 | 0.999950 | 0.999975 | 1.000000 |
| 随机森林 | 0.999958 | 0.999901 | 0.999950 | 1.000000 |
| 决策树 | 0.999852 | 0.999653 | 0.999827 | 0.999851 |
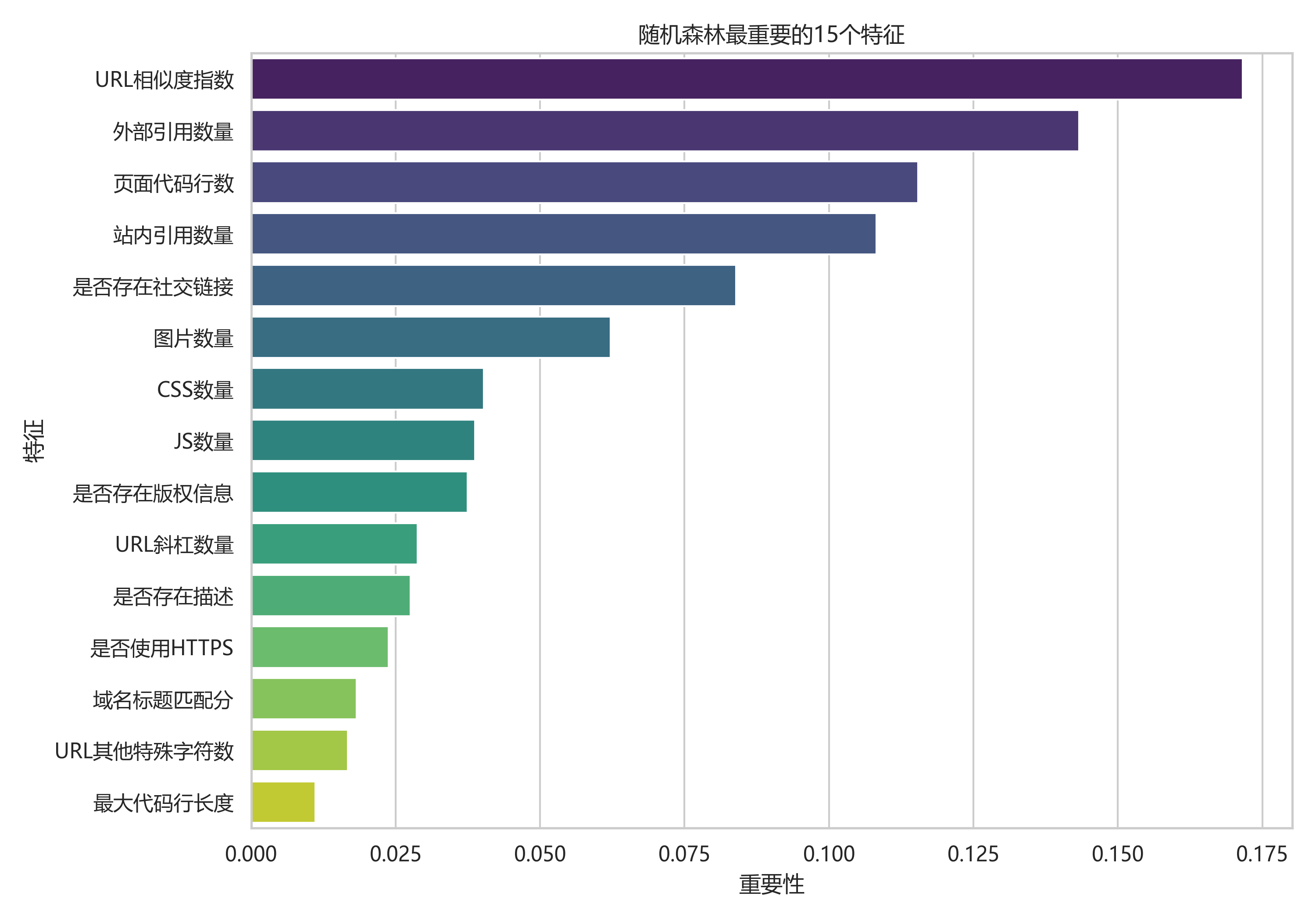
前四个变量的重要性合计约 0.5386,说明模型判断高度依赖 URL 相似度、外部引用、页面代码规模和站内引用结构。
URL 相似度均值 50.18,外部引用约 0.80,页面代码行数约 47.00。
页面代码行数约 379.48,外部引用约 6.60,图片约 10.95,JS 数量约 8.58。
| 规则前件 | 支持度 | 置信度 | 提升度 |
|---|---|---|---|
| 低相似度 | 0.250010 | 1.000000 | 2.335876 |
| 未使用 HTTPS | 0.217375 | 1.000000 | 2.335876 |
| 低相似度 + 长 URL | 0.189444 | 1.000000 | 2.335876 |
| 低相似度 + 高特殊字符占比 | 0.155309 | 1.000000 | 2.335876 |
关联规则适合作为线索初筛条件,不应直接作为处置依据,仍需结合域名、网页内容、举报记录和人工复核。
本次作业按照 CRISP-DM 流程,基于公开钓鱼网站数据完成了数据理解、预处理、分类识别、聚类分析和关联规则挖掘。恳请任课老师和同学们批评指正。